Blog
Kubernetes GPU Entitlements with DRA and vCluster
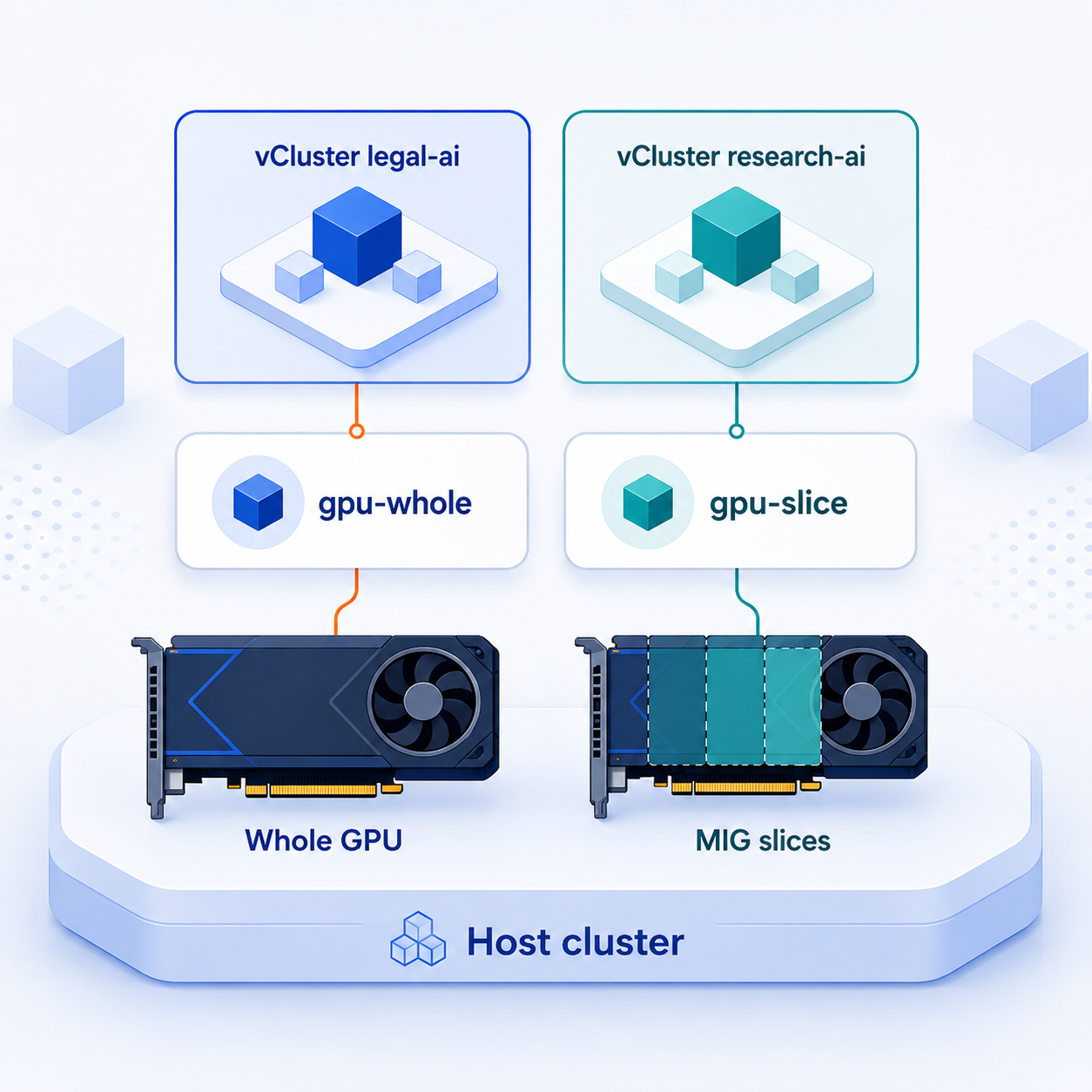
Sharing GPUs between tenants can be challenging when different teams have different entitlements. This guide demonstrates how to use a combination of Kubernetes DRA and vCluster to provide one tenant with access to dedicated A100 capacity and another with access to a MIG slice, while ensuring that each tenant can only see the GPU classes they are permitted to use.
Multi-Tenant Observability with vCluster: Centralized Metrics and Logs Using Prometheus, Loki, and Grafana
Discover how platform teams can implement centralized metrics and logging for multi-tenant Kubernetes using vCluster. This article walks through such an architecture for private-node vClusters, showing how a centralized observability stack can serve many isolated tenant clusters, laying the foundation for scalable, production-ready multi-tenant observability.
Stop Burning Your LLM Budget: Cost-Efficient LLMOps on Kubernetes
As LLM initiatives mature from pilot to production, infrastructure costs frequently scale faster than the value they deliver. The culprit is often operational inefficiency: idle GPUs, uncontrolled storage growth, cold start latency, and unplanned network egress. We examine the principal cost drivers in LLMOps on Kubernetes and provide actionable best practices across observability, GPU efficiency, throughput tuning, storage governance, and network topology.

LLMOps, a new aspect of platform engineering
For some time, large language models have no longer only been used in experimental playgrounds. They are increasingly used and embedded in enterprise-grade software to power customer support flows and knowledge systems, act as developer tooling, and support mission-critical applications. With this wide application of LLMs, new challenges regarding scalability, reliability, observability, cost efficiency and security must be taken into consideration. To tackle these, a new flavor of operations is currently emerging called “Large language model operations”, in short “LLMOps”. We will discover what LLMOps is, what it “contains” and create a high-level architecture of an LLMOps platform.

How vCluster Solves The Multi-Tenancy Compliance Dilemma
Compliance frameworks such as ISO 27001, SOC 2 and PCI-DSS provide little room for interpretation with regard to tenant isolation. In Kubernetes, this has traditionally meant having to make a difficult choice: either spin up separate clusters for every team or workload, or rely on namespace separation. vCluster offers an alternative to these two approaches. We will look at where conventional solutions fall short and how vCluster addresses these shortcomings.

Beyond the Model: The Hardware Fundamentals That Define Your AI Strategy
How does model size translate into real hardware requirements?
In this post, we break down the fundamentals every tech professional should know about LLM sizes (overview and intended use), memory demand (how to estimate it quickly and reliably), hardware choices and the VRAM bottleneck during inference.
