
LLMOps, a new aspect of platform engineering
veröffentlicht am 18.03.2026 von Lucas Brüning
For some time, large language models have no longer only been used in experimental playgrounds. They are increasingly used and embedded in enterprise-grade software to power customer support flows and knowledge systems, act as developer tooling, and support mission-critical applications. With this wide application of LLMs, new challenges regarding scalability, reliability, observability, cost efficiency and security must be taken into consideration. To tackle these, a new flavor of operations is currently emerging called “Large language model operations”, in short “LLMOps”. We will discover what LLMOps is, what it “contains” and create a high-level architecture of an LLMOps platform.
What is LLMOps
As with most other LLM technologies, LLMOps is very recent, and thus nearly every day there are new technologies, tools, architectures, and changes. This increases the difficulty of finding a proper definition and defining a proper scope of what LLMOps is.
In general, LLMOps combines and extends principles from MLOps and DevOps for LLM-specific tasks to ensure that LLM-Systems remain reliable, safe, and cost-efficient at scale. With that, it describes the discipline of deploying, monitoring, securing, evaluating, and maintaining large language models in multiple environments. This highlights the importance of LLMOps when it comes to keeping operations stable for LLMs and LLM workflows. To gain a better understanding of what LLMOps is, we need to define a common scope of what it does and what it should be capable of.
Scope
Model Deployment and model serving
LLMOps is used to deploy and serve the actual LLMs in different environments. For the case to serve and deploy self-hosted LLMs this also includes setting up the required infrastructure to handle the proper GPU (or other accelerators) and CPU workloads and scale them if needed. The deployment also creates a multi-model routing strategy in general, which enables us to automatically route specific requests to different kinds of models. For example, we could route simpler tasks to smaller models to improve the cost-efficiency. With multi-model routing, a proper load-balancing and failover strategy can be accomplished, which increases scalability and reliability in production systems.
It is recommended to set up an AI-Gateway to configure model routing rules and have a centralized API for different LLM-Providers or self-hosted LLMs. An example for an AI-Gateway could be the open-source project “LiteLLM” which we already discussed in a different blog article with all its advantages and capabilities.
Observability
Another important aspect of an LLMOps platform is to create a layer of observability for our LLMs. We need to extend our currently known metrics, such as resource and API usages or overall system availability, with LLM-specific metrics. These metrics could contain the latency of model responses, GPU and CPU compute usage and the used input, output, and reasoning tokens. With token usages, an LLMOps observability stack can accurately calculate model API costs, which is another important metric.
Beyond system-level metrics, observability should also cover model inference quality and retrieval-augmented generation (RAG) quality to detect performance degradations over time. For model quality, this can include metrics such as hallucination rate, factual correctness, answer relevance, consistency across repeated queries, and user feedback signals. For RAG systems, key indicators include retrieval precision and recall, context relevance, grounding (i.e., how well responses are supported by retrieved documents), and answer faithfulness to sources.
Another insightful part of LLMOps observability could be agent-level monitoring and tracing. Modern AI-Agents use a set of tools and can even spawn sub-agents. To properly observe and debug agent outputs, behaviors, and quality, it is necessary to trace and monitor each action of an agent. This includes tracking tool selection accuracy, tool success and failure rates, execution latency, and intermediate reasoning steps. This also enables metric collection for tools used by an agent.
Cost and Performance optimization
LLM systems can become expensive and slow quickly, especially when they are used at scale or when agents execute multiple tool calls per request. Therefore, cost and performance optimization is an essential LLMOps scope. The goal is to reduce cost per request and costs per token while meeting latency and reliability requirements.
Common strategies include already named model routing and multi-model setups, where simpler requests are served by smaller and cheaper models while complex tasks are routed to more capable models. This also improves performance significantly when it comes to smaller requests. Semantic caching, set up via RAG-Operations, can reduce redundant calls by reusing answers for similar queries. Prompt compression and context engineering reduce token usage, which directly affects both cost and latency. Token budgets and hard limits prevent exceptionally large prompts and protect against unexpected spending.
Performance gains can also be achieved by request batching, automatic scaling of computing infrastructure, and choosing optimal servers and regions. An observability stack is crucial to gain useful insights into where time and costs are spent.
RAG Operations
Retrieval-Augmented Generation (RAG) is one of the most common patterns to connect LLMs with company knowledge. Instead of relying on the model to "know" internal facts, the system retrieves relevant documents from a knowledge base and feeds them into the prompt. It can be an alternative to fine-tuning a model with the advantage of needing less computing power and fewer data points. RAG can also be used to set up semantic caching to lower the model latency and costs.
There are different flavors of RAG, each with varying levels of complexity and implementation cost. Traditional RAG relies on vector similarity search, while more advanced approaches such as GraphRAG incorporate structured knowledge graphs to improve reasoning and context retrieval. Another variant, the instructed retriever, uses task-specific instructions to guide retrieval more precisely.
Nevertheless, RAG operations include the maintenance of vector databases and embedding pipelines and even embedding models. This can be used to automatically update the knowledge base for the LLM once documents in the knowledge base change.
Prompt Management
Prompt management describes the creation and versioning of prompts and prompt templates. This enables a whole deployment and rollback process for prompts. It is possible to separate prompts into multiple versions and run evaluations and tests with them to ensure quality constraints. It also decouples the prompts from possible LLM applications, making it possible to change prompts and switch between prompt versions without triggering new application rollouts.
Architecture
All named scopes need to be tightly integrated with each other to form a proper and efficient LLMOps stack. The underlying diagram visualizes the components of the stack, including their relation to each other and how they can be integrated.
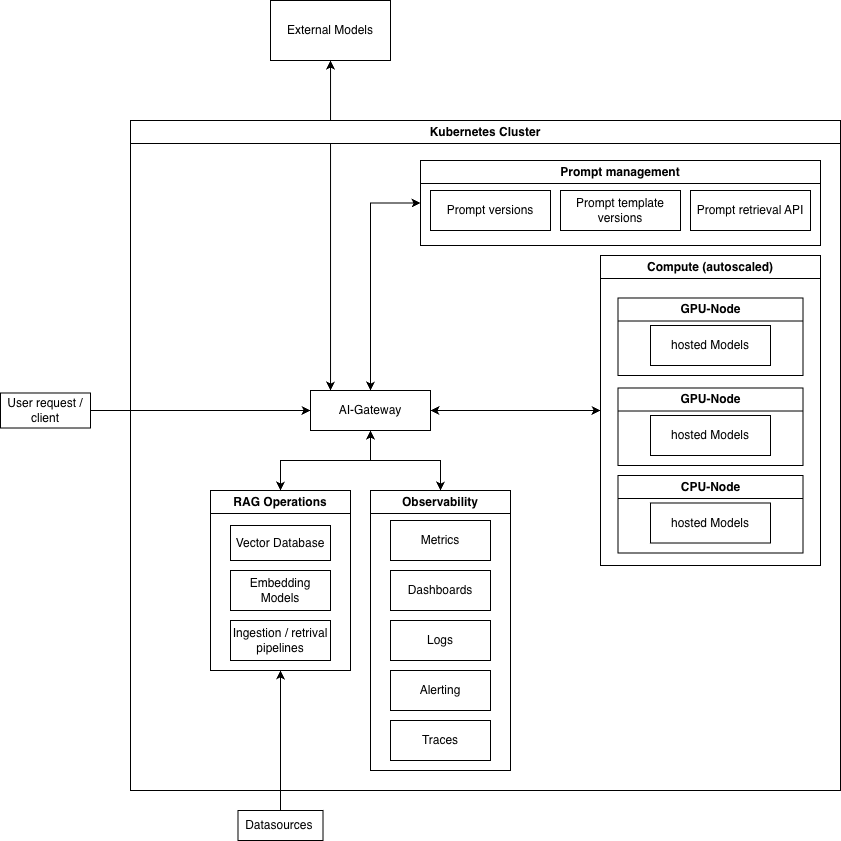
Everything starts with a user request, which is routed through the AI-Gateway our centralized entry point for all LLM interactions. This gateway acts as a unified abstraction layer over multiple model providers and deployments. It enables intelligent routing, load balancing, fallback strategies, and request shaping, ensuring resilience and flexibility. The connected LLMs can be hosted externally (e.g., via OpenAI, Anthropic, AWS Bedrock) or deployed internally on cloud GPUs, distributed compute clusters, or even on-prem infrastructure.
A key enabler for this architecture is Kubernetes (k8s), which provides the orchestration layer for deploying, scaling, and managing LLM services and supporting components. Kubernetes allows us to standardize deployments across environments, efficiently utilize GPU resources, implement autoscaling for inference workloads, and ensure high availability of critical services like the AI-Gateway, embedding pipelines, and vector databases. It also simplifies the operation of hybrid setups where self-hosted and external models coexist.
Because of the AI-Gateway we have an abstraction layer which eliminates vendor lock in and different vendor specific nuances. The LLMs relate to a prompt management system to fetch the different prompts and prompt templates in different versions in real time. The connection to our RAG operations is done via the AI-Gateway as well. The observability stack gathers observability signals from the whole system including hardware usage and specialized metrics from the underlaying inference engine. The AI-Gateway reports token usage metrics, costs and API-Calls to the observability stack creating a comprehensive picture of the current state of the LLMOps platform.
Summary
LLMOps brings the discipline of platform engineering to AI systems by making large language models operable in production. It covers the full lifecycle around prompts, models, gateways, observability, cost control, and retrieval systems so that LLM-powered applications can scale reliably, securely, and efficiently. In practice, LLMOps is not just about running models, but about building the operational foundation that turns experimental AI features into stable enterprise software.
If you see potential to extend your current platform with LLMOps capabilities or need dedicated consulting on how to integrate LLMOps into your workflows, then don’t hesitate to contact us so we can give you further explanation and work towards your goals together.