
Real-time telemetry data collection made simple: a proof of concept with NATS on Scaleway
veröffentlicht am 17.11.2025 von Giacomo Sirri
Collecting and visualizing telemetry data from thousands of vehicles in near real-time is no easy task. Discover how to design a distributed, scalable, and reliable cloud native application on Scaleway, an up-and-coming European cloud provider, using NATS (Neural Autonomic Transport System) as the core messaging system. Explore why NATS is the perfect technology for this use case, and how features like wildcards, Queue Groups, and JetStream enable secure and efficient communication between microservices.
Let’s imagine this scenario: a car manufacturer wants to equip its new vehicle fleet with IoT sensors that calculate the position (GPS), speed, state of charge, and torque of vehicles in real-time.
The goal is to build a cloud native application that gathers telemetry data detected by the sensors into a centralized data store, to allow real-time visualization and analysis of vehicle status.
In this technical post, we will go through the complete process of designing the system, from identifying the necessary cloud resources to outlining the architecture, while addressing key challenges of distributed applications such as scalability and reliability.
Some constraints to keep in mind
To make things more interesting, let’s also define some constraints that the system has to take into account:
- Sensors are embedded IoT devices with very limited CPU and memory resources.
- The software installed in the sensors is automatically executed when the vehicle starts, and it keeps running until the vehicle shuts down.
- Each sensor works independently from the others, which means that the sampling rate (i.e., the number of times per second a signal is produced) can vary significantly between the sensors.
- Vehicle-to-cloud communication must be secure and resilient.
- The protocol used to send data to the cloud must be lightweight, reliable, and fast.
- Data storage and visualization services must come from the same European cloud provider.
- The system must be scalable, having to potentially collect data from thousands of vehicles simultaneously.
The solution must use as few cloud resources as possible, in order to minimize cloud footprint and costs.
Choosing the technologies
Scaleway: more than just an EU sovereign cloud provider
Scaleway is a French cloud provider often cited as one of the major players in the European Sovereign Cloud market. Its global relevance and market share are still limited, but they will most likely grow in the future, as data sovereignty becomes more and more of a necessity for European enterprises.
Praised for its pricing, web console UI and environmental sustainability, Scaleway is a great choice to run your workloads in the cloud. And even though it doesn’t offer the same range of services of the Big 3, it has some surprising gems. One technology in particular stands out as unique.
This technology is NATS (Neural Autonomic Transport System), a cloud native and open source messaging system designed around performance, security and ease of use, which has been part of the CNCF landscape as an incubating project since 2018.
Why NATS is a good fit
NATS implements the publish-subscribe pattern: publishers send messages on communication channels called subjects (or topics), which subscribers can listen to. A NATS server mediates the communication by receiving messages from publishers and delivering them to the appropriate subscribers. Essentially, itprovides a data layer to allow communication between microservices in a cloud native environment.
What makes it really interesting, though, is the broadness of its features. Here you can have a look at how NATS compares to other popular messaging technologies: compared to Kafka, NATS is much leaner, with minimal infrastructure and configuration overhead, and its cloud-native design gives it an edge over MQTT in scenarios where scalability and high throughput is required.
In the next section, we’ll explore how the following NATS features play a key role in this application’s architecture:
Scaleway provides managed NATS accounts (i.e., servers) out of the box. No need for cumbersome installations and configurations, just provision the service and you’re ready to go!
What other resources do we need?
Next, we need a computing platform to host the subscriber workloads. Cloud native applications typically revolve around building containers and running them on Kubernetes. Scaleway offers managed Kubernetes clusters under the name of Kubernetes Kapsule. When creating a Kapsule cluster, you can choose the node type for your node pool and enable features such as autoscaling, autohealing, and node isolation.
As for the database, there are several options available on Scaleway. An interesting one is Serverless SQL Database, a fully-serverless database service for PostgreSQL that automatically scales storage and compute resources according to your workloads.
Compared to more traditional options like Scaleway’s Managed Database for PostgreSQL and MySQL, which charges a fixed amount regardless of usage, Serverless SQL makes you pay only for what you actually use. If you actively query or write data for less than two hours a day, then you’ll save more than 80% compared to the managed solution!
Obviously, we also need a data visualization service. One of the leading solutions in this field is Grafana, which natively supports PostgreSQL. We can run a Grafana container in the same Kubernetes cluster as the NATS subscribers, in order to avoid setting up additional infrastructure.
Finally, we want to securely save credentials for the database and the NATS server. Scaleway provides Secret Manager, a managed and secure storage service for sensitive data such as passwords and API keys.
Recap of needed technologies
Client side
- Custom C program executed locally via script (this is the official NATS C client used)
Server side
- Scaleway NATS account
- Scaleway Kubernetes Kapsule
Data storage and visualization
- Scaleway Serverless SQL database
- Grafana pod running in Kubernetes Kapsule
Credentials management
Scaleway Secret Manager
All of these resources are created, updated, and eventually destroyed via Terraform.
Designing the architecture
Since the architecture revolves around NATS, the first design challenge is determining how to bind publishers and subscribers. The goal is to ensure that subscribers can handle large message volumes efficiently, especially since scaling them in the cloud can quickly increase costs.
Approach #1: static assignments + vehicle discovery service
The most straightforward approach is to assign each vehicle to a specific subscriber, so that every subscriber can independently aggregate data published on the vehicle’s subjects.
This design requires a vehicle discovery service to track which vehicles are active and assign them accordingly. However, this component would be a single point of failure for the system and would soon become a bottleneck.
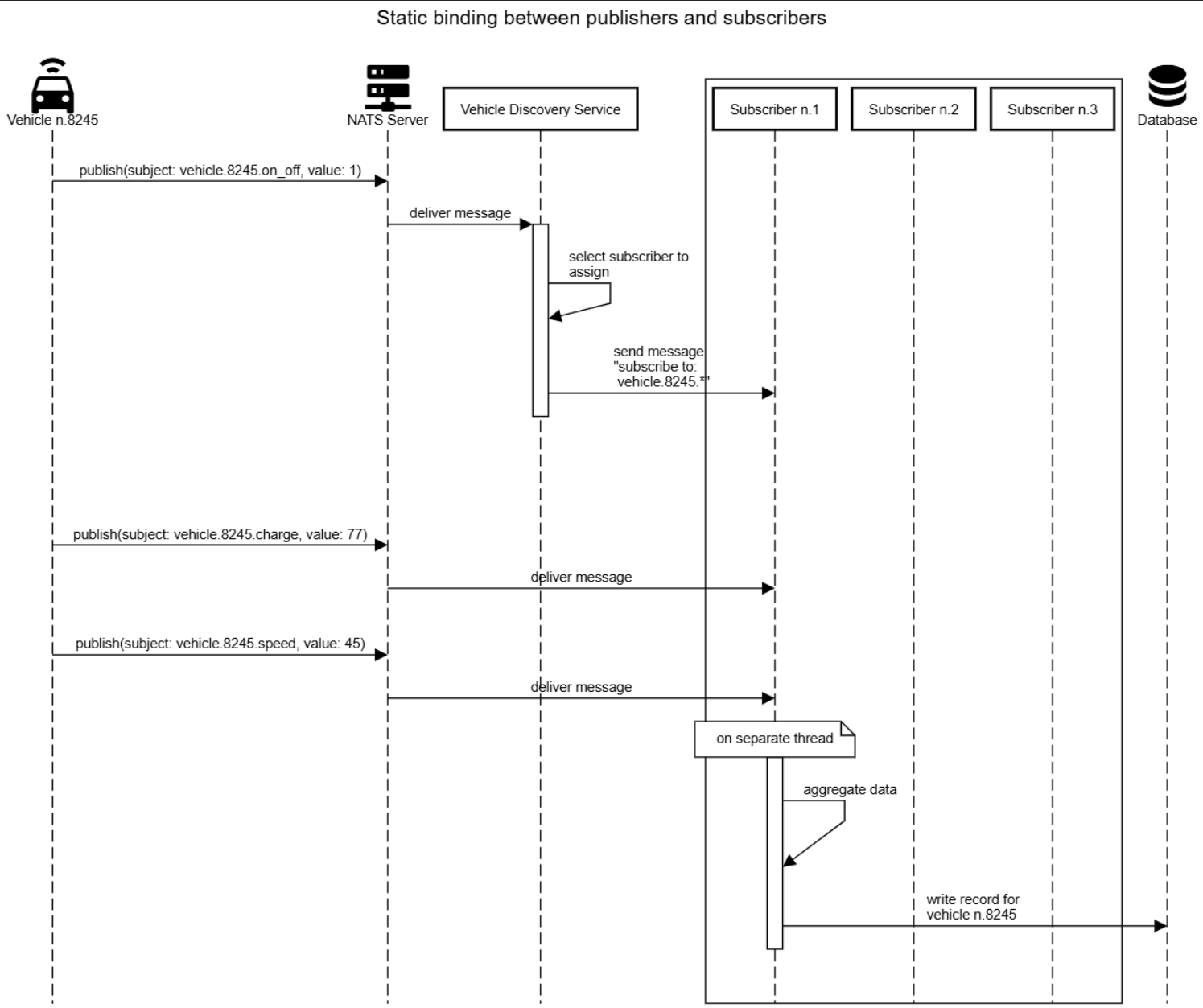
Approach #2: no assignments + data aggregation service
A more scalable alternative is to entirely avoid static assignments. In NATS, subscribers can use wildcardsto listen to multiple subjects at once. By subscribing to vehicle.*.*, they receive all the messages, from all vehicles and sensors, without manual coordination!
Now, we have to find a way for each subscriber to handle a distinct subset of incoming messages, so that the same message isn’t processed multiple times. This is where Queue Groups come into play. Within the same queue group, each message is delivered to only one randomly selected subscriber. This ensures automatic load balancing, fault tolerance, and scalability.
NATS can be enhanced with JetStream, which adds persistence by allowing messages to be saved and replayed at a later time. JetStream’s Key/Value Store feature provides buckets (i.e., associative arrays), where clients can store data as key-value pairs, similarly to what’s possible with proper key-value databases like Redis.
Subscribers can leverage the Key/Value Store to save the payload of the messages they receive (e.g., vehicle.4613.speed=95). From there, a data aggregation service periodically reads the latest values sent by the sensors, and writes a timestamped record to the PostgreSQL database for each vehicle.

And finally: let’s visualize data in Grafana
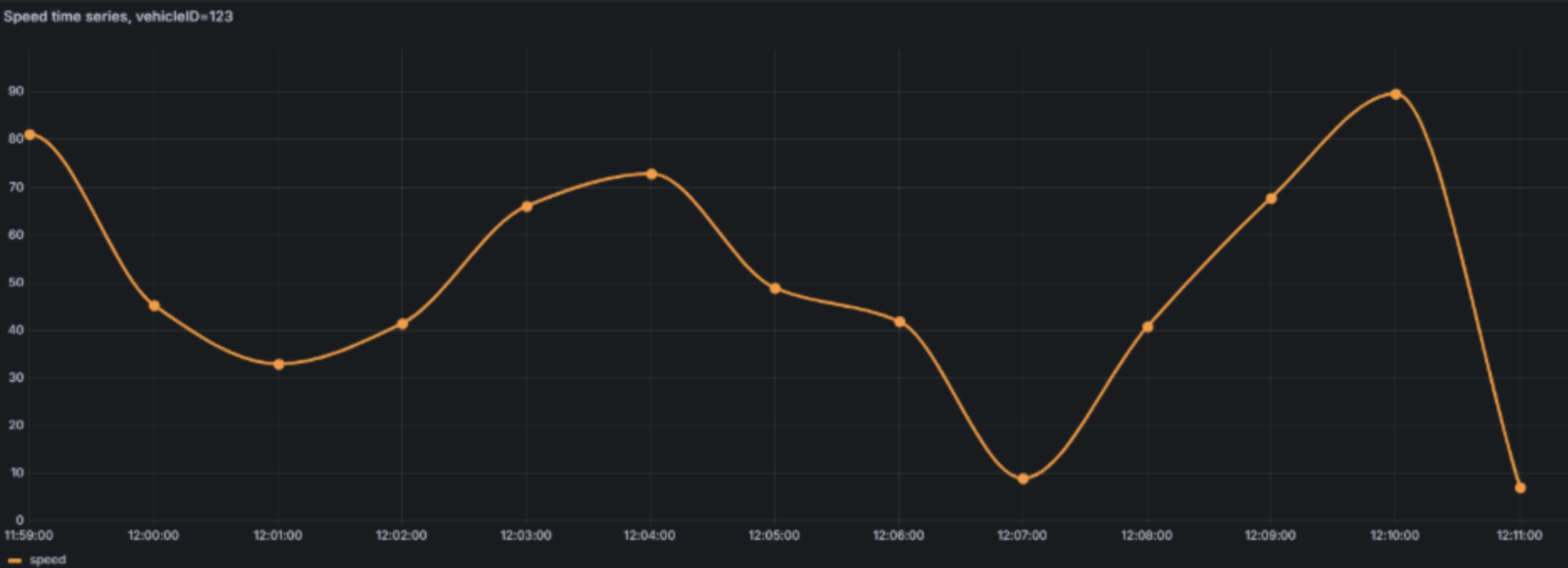
Once the aggregator writes records to the PostgreSQL database, we can access and visualize time seriesdata through Grafana, by connecting to the Grafana service endpoint in a browser.
The example below shows a Grafana dashboard displaying a vehicle’s speed over a 10-minute interval. The data was generated by running a local publisher simulating the speed sensor. Although the values were randomly generated, they still went through the system’s processing, showcasing its near real-time data collection capabilities.
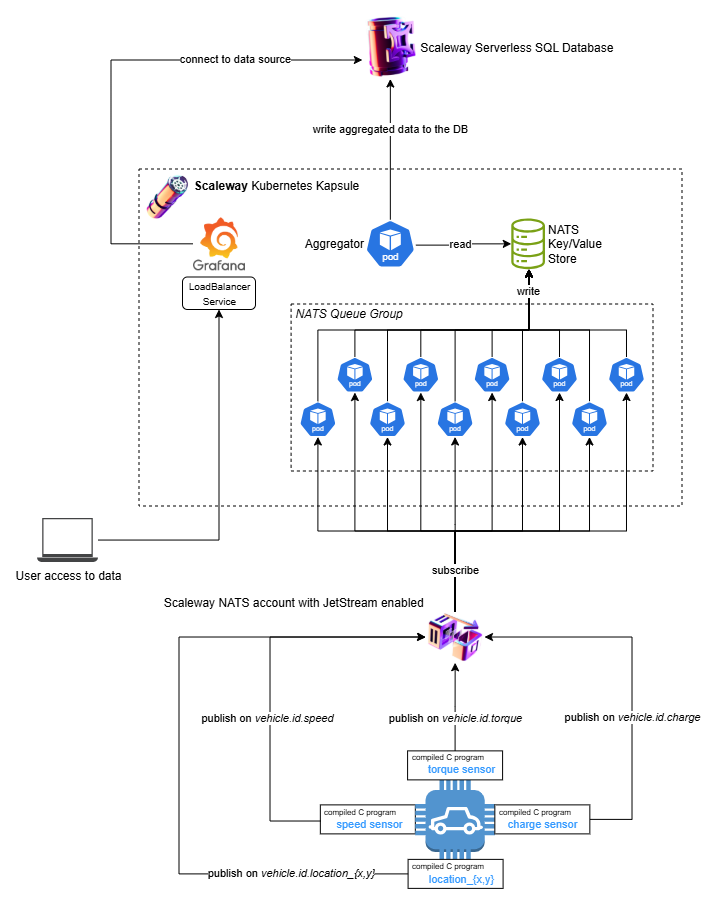
What does the architectural diagram look like?
The diagram below illustrates the complete architecture of the system:
Source code and potential improvements
You can find the complete source code for the project in this repository, where you can also dive deeper into some technical details explained in the README. The repository is in read-only mode, but you can fork it and use it as a starting point to build your own solution.
In this proof of concept, the aggregator is configured to read from the Key/Value Store bucket at the turn of every new minute. This frequency would likely be too low for a real-world scenario, as a vehicle can change its state really quickly, for example when accelerating.
You can reduce the interval, but below a certain threshold the current implementation would fail, as the aggregator would start a new read-write cycle before completing the previous one. A potential improvement would be to introduce multithreading in the aggregator’s core logic, allowing multiple cycles to run concurrently and independently.
Of course, this is just one of many possible optimizations. For example, you could add monitoring, improve resiliency by handling downtime in the aggregator service, or enable horizontal autoscaling for subscribers based on the number of incoming messages.
Summary
In this proof of concept, we started from a complex problem and built a cloud native solution from the ground up, using Scaleway’s innovative services like NATS. We explored two different architectural approaches, highlighting the advantages of avoiding direct binding between publishers and subscribers. We also took a closer look at key NATS features that make it a particularly suitable technology for this use case.
I really hope this inspires you to get hands-on with Scaleway and NATS. There are endless possibilities to explore, and you can also help make Scaleway an even better platform by joining its open-source community!