
Solving Kubernetes Multi-tenancy Challenges with vCluster
veröffentlicht am 30.05.2025 von Fabian Brundke
Erfahren Sie, wie vCluster die Einschränkungen der Mandantenfähigkeit von Kubernetes für interne Entwicklerplattformen durch die Erstellung isolierter virtueller Cluster innerhalb von Host-Umgebungen löst. Dieser technische Deep Dive untersucht, wie Plattformteams Benutzern die vollständige administrative Kontrolle über ihre Umgebungen ermöglichen und gleichzeitig eine angemessene Isolierung aufrechterhalten können – und damit die Ressourcenbeschränkungen auf Namespace-Ebene lösen, die typischerweise eine Herausforderung für mandantenfähige Architekturen darstellen. Erfahren Sie, wie vCluster Teams die Bereitstellung von clusterweiten Ressourcen wie CRDs ermöglicht und gleichzeitig die Sicherheit und Governance durch nahtlose Integration mit Sicherheitstools auf Host-Ebene gewährleistet.
Mehrmandantenfähigkeit verstehen
Wenn wir interne Entwicklerplattformen (IDP) für unsere Kunden aufbauen, ist Kubernetes oft eine gute Wahl als robuster Kern dieser Plattform. Dies liegt an seinen technischen Fähigkeiten und der starken Community, die das umgebende Ökosystem ständig erweitert. Ein häufiger Anwendungsfall für IDP ist die Unterstützung des Softwareentwicklungslebenszyklus (SDLC) mehrerer Mandanten (z. B. mehrere Anwendungen oder Softwareentwicklungsteams). Die Einführung von Kubernetes hilft dabei, Ressourcen zwischen diesen verschiedenen Mandanten zu teilen, was unter anderem zur Kostenoptimierung und Durchsetzung von Standards beiträgt, aber auch die Herausforderung mit sich bringt, Workloads voneinander zu isolieren. Dies wird als Multi-Tenancy (Mehrmandantenfähigkeit) bezeichnet, und für eine IDP müssen wir sicherstellen, dass diese Isolierung fair und sicher ist.
Multi-Tenancy mit nativen Kubernetes-Funktionen
Glücklicherweise bietet Kubernetes einige sofort einsatzbereite Funktionen, um die Isolierung in einer Multi-Tenant-Umgebung zu unterstützen. Diese Isolierung kann für die Steuerungs- und die Datenebene erfolgen. Lassen Sie uns diese Funktionen kurz beschreiben.
Isolation der Steuerungsebene
- Namespaces werden verwendet, um verschiedene Ressourcen für Mandanten in logischen Einheiten zu gruppieren. Dies ermöglicht zwar die effektive Anwendung von z. B. Sicherheitsrichtlinien, bietet jedoch keine Isolation an sich.
- Die rollenbasierte Zugriffskontrolle (RBAC) spielt eine entscheidende Rolle bei der Durchsetzung von Autorisierungen. Dies hilft dabei, den Zugriff auf API-Ressourcen für jeden einzelnen Mandanten zu beschränken oder zu verweigern, und kann mit Namespaces kombiniert werden.
- Ressourcenquoten (Resource Quotas) können verwendet werden, um Grenzen für den Ressourcenverbrauch einzelner Namespaces festzulegen. Dies ist nicht auf Rechenressourcen wie CPU und Speicher beschränkt, sondern kann auch für z. B. Speicherressourcen oder Objektzahlen definiert werden.
Isolierung der Datenebene
- Netzwerkrichtlinien (Network Policies) werden verwendet, um den ausgehenden und eingehenden Datenverkehr zu begrenzen, da standardmäßig die gesamte Netzwerkkommunikation erlaubt ist. Dies hilft, die Netzwerkisolierung zwischen Mandanten durchzusetzen.
- Die Isolierung des Speichers kann mit dynamischer Volume-Bereitstellung erreicht werden.
- Die Isolierung von Knoten wird durch die Bereitstellung dedizierter Knoten für die einzelnen Mandanten und die Beschränkung auf mandantenspezifische Workloads unterstützt, z. B. durch die Verwendung von Taints und Tolerations.
Diese Funktionen bieten zwar eine robuste Grundlage für Multi-Tenancy, reichen jedoch in einer ausgereiften IDP-Umgebung oft nicht aus. Insbesondere das Konzept der Namespaces wird zu einem limitierenden Faktor für die Isolierung auf der Ebene der Steuerungsebene. Betrachten wir die Situation, in der ein Team (im Folgenden betrachten wir einzelne Teams als einzelne Mandanten) eine bestimmte Custom Resource Definition (CRD) bereitstellen muss, die für die Ausführung eines bestimmten Tools erforderlich ist, das nur ihre Anwendung benötigt. Da CRDs auf Cluster-Ebene bereitgestellt werden müssen, sind sie nicht mit einem Namespace versehen. Daher kann das Team eine CRD nicht selbst bereitstellen (da ihr Zugriff gemäß den Isolationsanforderungen auf ihren Namespace beschränkt ist). Das bedeutet, dass es sich an das Plattform-Engineering-Team wenden muss, um Unterstützung anzufordern, wodurch den Plattform-Ingenieuren im Wesentlichen folgende Optionen bleiben:
- Die Anfrage ablehnen und möglicherweise das Team als Plattformnutzer verlieren, was wahrscheinlich auch zu einer negativen Reputation für die Plattform als Produkt führen würde.
- Dem Team mehr Rechte einräumen, damit es Ressourcen auf Cluster-Ebene bereitstellen kann, was jedoch dem Konzept der Mandantenisolation widerspricht.
- Bereitstellung der CRD für das Team, was auch bedeutet, dass man für die Verwaltung der Mandantenressourcen verantwortlich wird, was dem IDP-Konzept widerspricht und schnell zu einer unüberschaubaren Belastung werden kann (auf der anderen Seite kann diese Option die richtige Wahl sein, wenn mehrere Teams die CRD benötigen und es somit zu einem Plattformangebot werden kann).
- Erstellung eines dedizierten Clusters nur für dieses Team, auf das es vollen Zugriff hat, was die Kosten, den Betriebsaufwand und die Konfigurationsausbreitung erheblich erhöht.
Keine dieser Optionen ist in dem beschriebenen Anwendungsfall für den Plattformnutzer oder die Plattformingenieure wirklich überzeugend. Wie können wir dieses Dilemma lösen? Mit vCluster!
vCluster
vCluster ist ein Tool von LoftLabs, mit dem wir virtuelle Cluster erstellen können, die auf einem physischen Host-Cluster laufen. Diese virtuellen Cluster sind voll funktionsfähige Kubernetes-Cluster und bieten einen API-Server-Endpunkt.
Als solche sind sie ein überzeugendes Angebot zur Unterstützung der Isolierung in einer Multi-Tenancy-Umgebung. Wie funktioniert das?
Konzept
Aus Sicht des physischen Host-Clusters ist vCluster einfach eine Anwendung, die in einem Namespace ausgeführt wird. Diese Anwendung besteht aus zwei wichtigen Komponenten.
Zunächst gibt es die virtuelle Steuerungsebene, die Komponenten enthält, die Sie auch in jedem normalen Cluster finden:
- Kubernetes-API-Server zur Bearbeitung aller API-Anfragen innerhalb des virtuellen Clusters.
- Controller Manager, der für die Gewährleistung eines konsistenten Ressourcenstatus verantwortlich ist.
- Datenspeicher zum Speichern der Status der Ressourcen im virtuellen Cluster.
- Scheduler, der optional ist und anstelle des standardmäßigen Host-Schedulers verwendet werden kann.
Zweitens gibt es den Syncer. Diese Komponente ist für die Synchronisierung von Ressourcen aus dem virtuellen Cluster mit dem Host-Namespace verantwortlich, in dem vCluster ausgeführt wird. Dies ist notwendig, da vCluster selbst über kein Netzwerk und keine Knoten verfügt, in denen Workloads geplant werden können. Standardmäßig werden nur die Low-Level-Ressourcen wie Pods, ConfigMaps, Secrets und Services mit dem Host synchronisiert.
Das folgende Diagramm aus der offiziellen Dokumentation veranschaulicht die oben beschriebene Architektur. Wenn Sie an weiteren Details interessiert sind, empfehlen wir Ihnen dringend, die Dokumentation zu lesen.
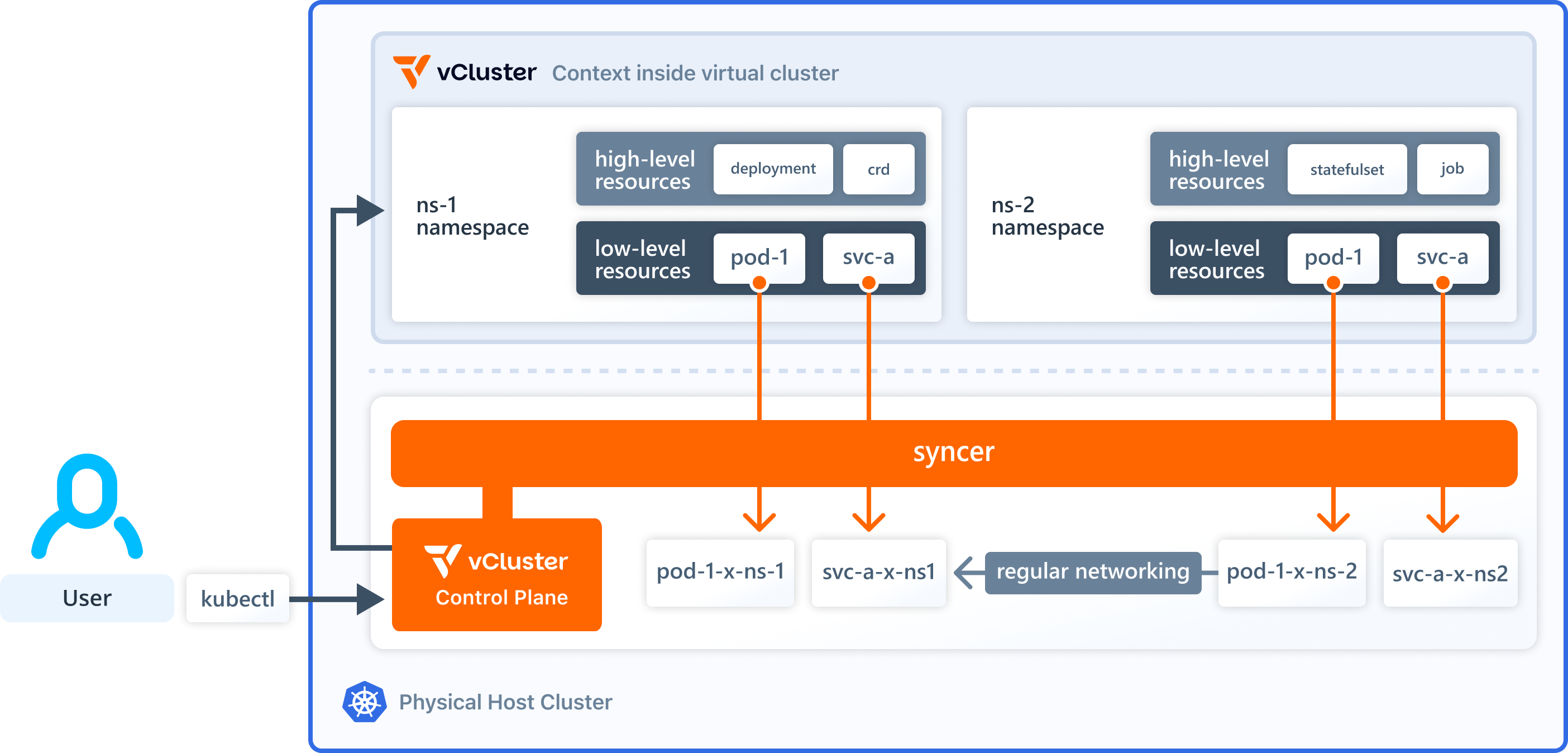
Was können Sie also mit einem virtuellen Cluster machen und wie hilft er bei der Mandantenfähigkeit? Teams können einen virtuellen Cluster beispielsweise über ein Self-Service-IDP-Angebot anfordern. Die IDP startet den virtuellen Cluster in einem Host-Namespace, der dem Team zugewiesen ist, und stellt dem anfordernden Team die erforderlichen Verbindungsdetails (z. B. über kubeconfig) zur Verfügung. Das Team kann dann den virtuellen Cluster nutzen, um z. B. die erforderlichen CRDs zusammen mit seinen Anwendungen bereitzustellen. Es kann den virtuellen Cluster auch nutzen, um so viele Namespaces zu erstellen, wie es benötigt. Aus Sicht des Hosts sind alle Workloads des virtuellen Clusters weiterhin auf den zugewiesenen Host-Namespace beschränkt. Auf diese Weise löst vCluster die Beschränkungen der Mandantenfähigkeit auf Namespace-Ebene für Teams und behält sie gleichzeitig aus Sicht des IDP bei. Lassen Sie uns einen virtuellen Cluster auf Basis des kostenlosen vCluster-Kernangebots starten, um ihn in Aktion zu sehen.
Praktische Übungen
Voraussetzungen
- Zugriff auf einen laufenden Kubernetes-Cluster, der als Host dient (für diese Demo wird ein lokaler colima-Cluster mit Kubernetes v1.32 verwendet).
- kubectl für die Interaktion mit dem Host und dem virtuellen Cluster.
- vCluster CLI zur Installation eines virtuellen Clusters (Hinweis: Andere Optionen wie Helm, Terraform, ArgoCD und Cluster API werden ebenfalls unterstützt; in dieser Demo wird vCluster 0.24.1 verwendet).
- Optional: Da Sie regelmäßig zwischen dem Host und dem virtuellen Cluster wechseln müssen, sollten Sie die Installation von kubectx in Betracht ziehen.
Bereitstellen eines virtuellen Clusters
Mit Zugriff auf einen Kubernetes-Cluster verwenden wir die vCluster-CLI, um einen virtuellen Cluster zu starten:
- Run
vcluster create tenant-a-vcluster --namespace tenant-a
, um diesen virtuellen Cluster zu erstellen. Dadurch wird automatisch ein Eintrag zu Ihrer kubeconfig hinzugefügt und Ihr aktueller Kontext auf den virtuellen Cluster geändert. Wenn Siekubectl get namespace
ausführen, sollten Sie die folgende Ausgabe sehen, die mit der Ausgabe in jedem physischen Cluster vergleichbar ist:NAME STATUS AGE default Active 1m05s kube-node-lease Active 1m05s kube-public Active 1m05s kube-system Active 1m05s
- In Ihrem Host-Cluster sehen Sie einen neuen Namespace namens tenant-a, der zwei Pods enthält:
- vCluster-Pod, der die Control-Plane- und Syncer-Container enthält
- core-dns, um sicherzustellen, dass Pods und Dienste sich gegenseitig anhand von Hostnamen im virtuellen Cluster finden können. Dieser core-dns-Pod wurde vom virtuellen Cluster mit dem Host-Cluster synchronisiert.
Workload bereitstellen
Als nächsten Schritt stellen wir eine Beispiel-Workload bereit, um zu sehen, was im virtuellen und im Host-Cluster passiert:
- Starten Sie innerhalb des virtuellen Clusters einen einfachen nginx-Pod im Standard-Namespace, indem Sie folgenden Befehl ausführen
kubectl run nginx --image=nginx
- Im Host-Cluster sehen Sie, dass der Syncer den nginx-Pod im Namespace
tenant-ades virtuellen Clusters mit einem angepassten Namen platziert hat, der aus Pod, Namespace und virtuellem Cluster besteht:nginx-x-default-x-tenant-a-vcluster - Da der nginx-Pod auf dem Host ausgeführt wird, kann er von anderen Workloads, die auf dem Host ausgeführt werden, wie jede andere reguläre Workload erreicht werden, sofern keine Einschränkungen wie Netzwerkrichtlinien bestehen. Um dies zu testen, können Sie beispielsweise die IP-Adresse des nginx-Pods im Host-Cluster abrufen:
NGINX_IP=$(kubectl get pod nginx-x-default-x-tenant-a-vcluster -n tenant-a --template '{{.status.podIP}}')
und dann Folgendes ausführen:kubectl run temp-pod --rm -it --restart=Never --image=curlimages/curl -- curl $NGINX_IP
Dies sollte einige HTML-Daten von nginx ausgeben, die anzeigen, dass die Anfrage erfolgreich war.
CRD bereitstellen
- Stellen Sie das folgende CRD auf dem virtuellen Cluster bereit:
kubectl apply -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/crds/crontabs.yaml
- Stellen Sie dann eine entsprechende benutzerdefinierte Ressource (CR) auf dem virtuellen Cluster bereit:
kubectl apply -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/resources/crontab.yaml
Sie erhalten eine Erfolgsmeldung, dass das Objekt erstellt wurde:crontab.stable.example.com/my-new-cron-object created - Versuchen Sie, dieselbe CR (nicht CRD) auf dem Host-Cluster bereitzustellen. Sie erhalten eine Fehlermeldung, die darauf hinweist, dass die entsprechende CRD nicht installiert ist, da sie nur im virtuellen Cluster verfügbar ist.
Zusammenfassung der praktischen Übung
Anhand dieser sehr einfachen praktischen Übung können wir sehen, wie einfach es ist, virtuelle Cluster zu erstellen, die wie normale Cluster aussehen und sich auch so verhalten. Die auf dem virtuellen Cluster bereitgestellte Workload wird mit dem Host-Cluster synchronisiert, wo sie sich wie eine normale Cluster-Workload verhält. Da der virtuelle Cluster über einen eigenen API-Server und Datenspeicher verfügt, können wir beispielsweise CRDs bereitstellen, die nur dort und nicht auf dem Host verfügbar sind. Diese Isolierung auf der Ebene der Steuerungsebene ist in einer Multi-Tenant-Umgebung sehr wertvoll und kann die eingangs beschriebene Herausforderung lösen.
Interaktion mit Host-Anwendungen
Mittlerweile ist klar, dass vCluster ideal für Plattformnutzer ist, die Ressourcen ohne Namespace verwalten möchten, aber wie sieht es mit dem Plattform-Engineering-Team aus? In der Regel stellt dieses Team einen Anwendungsstack bereit, der ihm und den Benutzern unter anderem dabei hilft, Sicherheit, Kosteneffizienz und Compliance zu gewährleisten. Funktionieren die Tools in diesem Stack auch für die virtuellen Cluster wie erwartet, obwohl sie auf dem Host-Cluster bereitgestellt werden? Als Beispiel betrachten wir Falco (erkennt Sicherheitsbedrohungen zur Laufzeit) und Kyverno(definiert Richtlinien, die als Leitplanken für die Cluster-Workload dienen) und sehen uns an, wie sie mit der virtuellen Cluster-Workload interagieren.
Falco
Da Falco Teil des Plattform-Stacks ist, müssen wir es zunächst auf dem Host-Cluster installieren (siehe offizielle Dokumentation):
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
helm install --replace falco --namespace falco --create-namespace --set tty=true falcosecurity/falco
falco bereitgestellt (die Demo verwendet die Chart-Version 4.21.3). Je nach Anzahl der Knoten im Host-Cluster sollten Sie die entsprechenden Pods sehen, wenn die Installation erfolgreich war: kubectl get pods -n falcoFalco verfolgt verdächtige Aktivitäten wie das Erzeugen einer Shell in einem Container oder das Öffnen einer sensiblen Datei.
Um die Funktionalität und Interaktion mit der Workload aus dem virtuellen Cluster zu testen, verwenden wir erneut den nginx-Pod, den wir im Rahmen der Demo bereitgestellt haben:
- Beobachten Sie die Falco-Protokolle auf dem Host-Cluster:
kubectl logs ds/falco -n falco -f - Extrahieren Sie den Inhalt der Datei
etc/shadowim nginx-Pod (diese Datei gilt als sensibel, da sie Passwortinformationen enthält):kubectl exec -it nginx -- cat etc/shadow - In den Falco-Protokollen sollte nun eine Warnung für diese aufgezeichnete verdächtige Aktivität angezeigt werden:
Warning Sensitive file opened for reading by non-trusted program ...
Da vCluster Workloads vom virtuellen Cluster mit dem Host synchronisiert, kann Falco diese Art von Aktivität erkennen, da sie für Falco wie eine normale Host-Workload erscheint. Das ist sowohl für die Plattformnutzer als auch für die Plattformingenieure eine gute Nachricht, da bei der Verwendung von vCluster keine Neukonfiguration von Falco erforderlich ist.
Kyverno
Genau wie Falco müssen wir zunächst Kyverno auf dem Host-Cluster installieren (siehe offizielle Dokumentation):
helm repo add kyverno https://kyverno.github.io/kyverno/
helm repo update
helm install kyverno kyverno/kyverno -n kyverno --create-namespaceNach erfolgreicher Installation läuft Kyverno im Namespace kyverno (die Demo verwendet die Chart-Version 3.4.1):kubectl get pods -n kyverno
Regeln validieren
app.kubernetes.io/name gekennzeichnet sind:kubectl apply -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/kyverno-policies/require-labels.yaml
events sowohl für den Host als auch für den virtuellen Cluster überprüfen:- Führen Sie für den virtuellen Cluster-Namespace auf dem Host-Cluster Folgendes aus:
kubectl events -n tenant-a | grep PolicyViolation
Da keine der Workloads in diesem Namespace über das erforderliche Label verfügt, sehen wir viele Validierungsfehler, wie wir sie von Kyverno erwarten würden:policy require-labels/check-for-labels fail: validation error: The label app.kubernetes.io/name is required. - Führen Sie nun für den virtuellen Cluster Folgendes aus:
kubectl events | grep PolicyViolation
Für den nginx-Pod aus der Demo auf dem virtuellen Cluster wird dieselbe Validierungsfehlermeldung angezeigt wie für den synchronisierten nginx-Pod auf dem Host-Cluster. Dies zeigt, dass Verstöße gegen Richtlinien, die vom Plattformteam auf dem Host-Cluster verwaltet werden, für Benutzer des virtuellen Clusters transparent sichtbar sind. Der Grund dafür ist, dass Ereignisse vom Host mit dem virtuellen Cluster synchronisiert werden. Es ist jedoch wichtig zu beachten, dass dieser Prozess asynchron abläuft, d. h. Ereignisse werden zuerst auf dem Host und dann im virtuellen Cluster angezeigt.
Die oben bereitgestellte Richtlinie ist auf Audit eingestellt, was bedeutet, dass bei Verstößen gegen die Richtlinie Warnungen ausgegeben werden, die Bereitstellung der Workload jedoch nicht blockiert wird. Schauen wir uns an, was passiert, wenn wir dieselbe Richtlinie im Modus Enforce bereitstellen:
- Rollen Sie die neue Richtlinie auf dem Host-Cluster aus:
kubectl apply -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/kyverno-policies/require-labels-enforce.yaml - Stellen Sie einige Beispiel-Workloads auf dem virtuellen Cluster ohne das erforderliche Label bereit:
kubectl run nginx-enforce --image=nginx - Sehen Sie sich den Pod an:
kubectl describe pod nginx-enforce
Sie werden sehen, dass der Pod im virtuellen Cluster im Statuspending(ausstehend) festhängt. Dies bedeutet, dass das Manifest im vCluster-Datenspeicher gespeichert wurde, aber im Status „ausstehend” verbleibt, da es nicht mit dem Host-Cluster synchronisiert werden kann, da die dortige Richtlinie die Anforderung des Labelsapp.kubernetes.io/namefür Workloads erzwingt.
Wenn Sie versuchen würden, dieselbe Workload direkt auf dem Host-Cluster bereitzustellen, würde Kyverno die Bereitstellung sofort mit einer Fehlermeldung blockieren. Im Vergleich zum virtuellen Cluster würde nichts im Datenspeicher des Host-Clusters gespeichert werden.
Mutationsregeln
Neben den Regeln in Kyverno-Richtlinien, die Ressourcen validieren, gibt es noch eine weitere wichtige Art von Regeln. Dabei handelt es sich um Mutationsregeln, mit denen Ressourcen geändert werden können, und deren Verhalten wir ebenfalls testen möchten. Dazu verwenden wir eine Richtlinie mit Regeln für die folgenden Mutationen:
- Fügen Sie das Label
foo: barhinzu - Fügen Sie die Anmerkung
foo: barhinzu - Fügen Sie Ressourcenanforderungen für CPU und Speicher hinzu, falls diese nicht vorhanden sind
Sie können sich die Richtlinie hier ansehen:
- IInstallieren Sie die Richtlinie auf dem Host-Cluster:
kubectl apply -f kubectl apply -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/kyverno-policies/add-labels-annotations-resources.yaml - Entfernen Sie die Enforce-Richtlinie von oben, um die Bereitstellung neuer Workloads nicht zu blockieren:
kubectl delete -f https://raw.githubusercontent.com/Liquid-Reply/vcluster-idp-tools/refs/heads/main/kyverno-policies/require-labels-enforce.yaml - Da die Mutationen nur auf neu erstellte Pods angewendet werden, stellen wir einen weiteren nginx-Pod auf dem virtuellen Cluster bereit:
kubectl run nginx-mutate --image=nginx - Um zu überprüfen, ob die Mutationen korrekt angewendet wurden, können Sie sich den Pod ansehen:
kubectl describe pod nginx-mutate
Sie werden sehen, dass sowohl das Label foo: bar als auch die Anmerkung auf den Pod im virtuellen Cluster angewendet wurden, die Ressourcen jedoch nicht festgelegt wurden. Im Gegensatz dazu sind beim synchronisierten Host-Pod nicht nur das Label und die Anmerkung festgelegt, sondern auch die Ressourcen gemäß der Richtlinie angepasst worden – was zu erwarten ist, da Kyverno auf dem Host ausgeführt wird. Der Grund dafür ist, dass genau wie bei den Ereignissen (wie zuvor beschrieben) die Labels und Annotationen vom Host zum virtuellen Cluster synchronisiert werden, dies jedoch nicht für alle Objekteigenschaften gilt. Tatsächlich wird der größte Teil der Pod-Spezifikation nicht zurück synchronisiert. Diese bidirektionale Synchronisierung wird in der offiziellen Dokumentation näher beschrieben, zusammen mit einer Übersicht darüber, was tatsächlich synchronisiert wird.
Auswirkungen
Betrachtet man Pods nur unter dem Gesichtspunkt der Funktionalität, könnte es ausreichend sein, Kyverno ausschließlich vom Host-Cluster aus zu verwenden, da die Richtlinien auf die synchronisierten Pods auf dem Host angewendet werden. Diese synchronisierten Pods sind die tatsächlichen Workloads, die auf den zugrunde liegenden Knoten ausgeführt werden, sodass sie den definierten Richtlinien der internen Entwicklerplattform entsprechen. Der Nachteil dieser Lösung besteht darin, dass der Mandant, der den virtuellen Cluster nutzt, keinen Einblick in alle Änderungen hat, die auf seine Workload angewendet werden, da diese nicht vom Host zurückgesynchronisiert werden. Dies kann zu einer schlechten Entwicklererfahrung für die Plattform führen.
Noch wichtiger ist es, zu beachten, dass in dieser Konfiguration die Kyverno-Richtlinien nur auf Objekte angewendet werden können, die tatsächlich vom vCluster mit dem Host synchronisiert werden (standardmäßig werden nur Pods, Secrets, Configmaps und Services synchronisiert). Beispielsweise wird eine Deployment-Ressource im vCluster nicht mit dem Host synchronisiert. Die Folge ist, dass Host-Kyverno-Richtlinien, die auf Deployments abzielen (z. B. um sicherzustellen, dass eine Mindestanzahl von Replikaten definiert ist), keine Wirkung zeigen.
Die gute Nachricht ist, dass es einige Möglichkeiten gibt, diese Konfiguration zu verbessern:
- Installieren Sie zusätzlich Kyverno und die Richtlinien im virtuellen Cluster: Dadurch werden alle Mutationen und Validierungen für das Team, das den virtuellen Cluster nutzt, transparent. Das Team kann nun auch eigene Richtlinien bereitstellen und alle verfügbaren Kyverno-Funktionen nutzen. Der Nachteil ist, dass die zusätzliche Kyverno-Installation Ressourcen und Wartungsaufwand erfordert.
- Verwenden Sie die Kyverno-Integration, eine vCluster-Unternehmensfunktion: Dies hilft dabei, Richtlinien innerhalb der virtuellen Cluster mit nur einer einzigen Kyverno-Installation auf dem Host durchzusetzen. Eine bemerkenswerte Einschränkung hierbei ist jedoch, dass Sie andere Ressourcen auf dem Host-Cluster nur mit der Ressourcenbibliothek-Funktion von Kyverno nachschlagen können.
- Derzeit können die Funktionen von vCluster tatsächlich durch Plugins erweitert werden, um benutzerdefinierte Logik auszuführen. Es ist jedoch zu beachten, dass diese benutzerdefinierte Logik entwickelt und gewartet werden muss, was einen erheblichen Aufwand bedeuten kann. Darüber hinaus scheint die breitere Akzeptanz dieser Funktion begrenzt zu sein, sodass eine weitere Unterstützung dieser Funktion in Zukunft möglicherweise nicht garantiert ist.
Zusammenfassung
Wir haben untersucht, wie vCluster die Einschränkungen der nativen Kubernetes-Mandantenfähigkeit für interne Entwicklerplattformen (IDPs) auf der Ebene der Steuerungsebene behebt. Kubernetes bietet zwar eine grundlegende Isolierung durch Namespaces, RBAC und andere Funktionen, diese reichen jedoch nicht aus, wenn Teams clusterweite Ressourcen wie CRDs bereitstellen müssen.
vCluster löst dieses Problem, indem es virtuelle Kubernetes-Cluster innerhalb eines Host-Clusters erstellt. Dadurch haben Teams die volle administrative Kontrolle innerhalb ihrer isolierten Umgebung und können gleichzeitig die richtigen Einschränkungen aus Sicht der Plattform aufrechterhalten.
Wir haben gezeigt, wie Workloads zwischen virtuellen und Host-Clustern synchronisiert werden, und die Interaktion und Kompatibilität mit Falco und Kyverno untersucht. Zwar gibt es einige Herausforderungen bei der Synchronisierung, insbesondere mit Kyverno, aber wir haben gelernt, dass die eigentliche Workload auf dem Host-Cluster läuft und somit ordnungsgemäß von Host-Anwendungen verwaltet wird, was sowohl für Plattformingenieure als auch für Benutzer ein wichtiger Aspekt ist.
Outlook
Während wir uns oben auf die Verbesserung der Isolierung der Steuerungsebene konzentriert haben, haben wir nicht diskutiert, wie die Isolierung der Datenebene verbessert werden kann. Vor kurzem hat LoftLabs vNode angekündigt, um genau diese Herausforderung anzugehen. Es wird interessant sein zu sehen, wie genau sich dieses Tool in eine ausgereifte Multi-Tenancy-Lösung einfügt und wie vCluster und vNode zusammenarbeiten werden. Als nächsten Schritt werden wir bei Liquid Reply diese Kombination testen, um die Möglichkeiten zu bewerten.