
Entwicklung einer einheitlichen LLM API Plattform mit LiteLLM
veröffentlicht am 22.09.2025 von Lucas Brüning
Dieser Blog behandelt das Identifizieren der Vorteile und Herausforderungen einer Architektur mit mehreren LLM-Providern und wie diese mit der Open-Source-Software „LiteLLM“ gelöst werden können. Dazu werden die unterschiedlichen Features von LiteLLM vorgestellt und erklärt, warum das Zentralisieren von LLM-Providern das Verwalten von Benutzern, Berechtigungen und Kosten erleichtert. Dies führt zusätzlich zu einer kürzeren Entwicklungszeit für agentenbasierten Workflows and LLM-Applikationen.
Warum mehrere LLMs benutzt werden sollten
In den letzten Jahren kam eine Vielzahl neuer LLMs mit unterschiedlichen Größen und Fähigkeiten auf den Markt. Dies hat direkten Einfluss auf unsere Entscheidung, die richtigen LLMs für unsere Workflows auszuwählen. Der einfachste Weg ist das neueste, größte und beste Modell eines bekannten LLM-Anbieters wie OpenAI oder Anthropic zu wählen, um den Entscheidungsprozess zu vereinfachen und zu beschleunigen. Dies mag zwar für kleinere, einfachere Anwendungsfälle funktionieren, doch kann die Verwendung eines einzelnen LLMs bei komplexeren Workloads an seine Grenzen stoßen. Ein Beispiel hierfür wäre die Verwendung mehrerer KI-Agenten für einen automatisierten Entwicklungsprozesses, der wie folgt aussehen könnte:

In diesem Beispiel werden drei Agents verwendet:
- Planner-Agent: für das Entgegennehmen der Eingaben eines Benutzers, zum Planen der entsprechenden Entwicklungsaufgaben und zum Delegieren dieser Aufgaben an den Web- und/oder Coding-Agents.
- Coding-Agent: zum Generieren von Code und Bearbeiten von Dateien oder Ausführen von Befehlen, zur Kommunikation mit dem Web-Agenten.
- Web-Agent: zum Suchen von Dokumentationen oder anderen Informationen im Internet, zur Kommunikation mit dem Codierungs-Agenten.
In einem solchen Anwendungsfall ist es ratsam, für jeden Agent ein anderes, für die jeweilige Aufgabe optimiertes LLM zu verwenden. Beispielsweise könnten hier die Claude-Modelle für die Codegenerierung verwendet werden, während eines der Perplexity-AI-Modelle für die Suche im Internet benutzt werden könnte. Für die Planung kann aus Kostengründen ein kleineres OpenAI-Modell verwendet werden. Auf diese Weise lassen sich bessere Ergebnisse erzielen und gleichzeitig Kosten einsparen.
Dieses Beispiel lässt sich auf verschiedene Weise erweitern und abwandeln. Vielleicht soll eine Art Bild- oder Videoanalyse mit Googles Gemini eingebunden werden, oder Sie möchten, dass bestimmte Aufgaben von einem europäischen Modellanbieter wie Mistral AI ausgeführt werden. Vielleicht sollen aus Compliance-Gründen Open-Source-Modelle auf eigenen Servern benutzt werden oder die Kosteneffizienz oder Leistung soll mit fein abgestimmten kleinen Sprachmodellen (SLMs) verbessert werden. Die Verwendung mehrerer Modelle trägt auch dazu bei, die Anforderungen an Ausfallsicherheit und Skalierbarkeit zu erfüllen. Im Falle eines Ausfalls können Sie auf verschiedene Cloud- oder lokale Modelle ausweichen oder diese zur Lastverteilung zwischen verschiedenen Anbietern nutzen.
Die Verwendung einer breiten, aufgabenspezifischen Modellpalette kann die Effizienz und Leistung Ihrer Workflows steigern. Mit der wachsenden Anzahl unterschiedlicher Modelle in einem Workflow werden jedoch automatisch mehrere LLM-Anbieter zusätzlich zu potenziellen lokalen Modellen benutzt. Eine solche providerübergreifende Architektur bringt ihre eigenen Herausforderungen bei der Verwendung und Wartung von Workflows mit sich.
Die Herausforderungen bei mehreren LLM-Anbietern
In den letzten Jahren sind viele neue Modellanbieter auf den Markt gekommen, darunter eine Vielzahl von Modellangeboten in unterschiedlichen Größen und für unterschiedliche Anwendungsfälle. Dies ermöglicht die aufgabenspezifische Verwendung von Modellen in einem agentenbasierten Workflow. Obwohl eine große Auswahl an Modellen vorteilhaft ist, führt sie zur Nutzung mehrerer Anbieter. Selbst die Nutzung einiger weniger Anbieter kann verschiedene Probleme verursachen. Die häufigsten dieser Probleme sind unterschiedliche API-Spezifikationen, die Verwaltung von Benutzern und die Messung der Modellkosten.
Unterschiedliche API-Spezifikationen
Die meisten LLM-Anbieter, LLM-Anwendungen und lokale LLM-Inferenzsoftware implementieren standardisierte API-Endpunkte und Datenaustauschformate, die den API-Standards von OpenAI entsprechen und sie somit „OpenAI-kompatibel” machen. Dadurch können Entwickler verschiedene Anbieter nutzen, ohne die Anfragedaten für die Verwendung der API ändern zu müssen. Obwohl sich die OpenAI-Kompatibilität etabliert hat, kann es dennoch erforderlich sein, Teile einer Anwendung zu ändern, um mit unterschiedlichen Provider-APIs oder unterschiedlichen Authentifizierungsmechanismen umzugehen. Die Anwendung muss möglicherweise auch unterschiedliche SDKs für jeden Modellprovider verwenden.
Benutzerverwaltung
Die Verwendung mehrerer Modellanbieter bedeutet, dass jeder Anbieter über eine eigene Benutzerverwaltung verfügt. Jedes Mitglied eines Teams benötigt ein Konto für jeden verwendeten LLM-Anbieter. Darüber hinaus soll möglicherweise ein oder mehrere API-Schlüssel pro Benutzer oder pro Anwendung verwenden werden, um einen separations of concerns Ansatz zu nutzen. Aber selbst mit unterschiedlichen API-Schlüsseln für unterschiedliche Anwendungszwecke kann es schwierig sein, mit den aktuellen Anbietern eine solide Zugriffsverwaltung zu implementieren. Einige Anbieter erlauben es nicht, API-Schlüsseln die Berechtigung zu erteilen, nur auf bestimmte Modelle zu werden. In diesem Fall kann jeder Benutzer mit einem API-Schlüssel jedes mögliche Modell eines Anbieters nutzen, auch die teuersten. Die Verwendung von On-Premise-Modellen erschwert die Benutzerverwaltung zusätzlich, da in diesem Fall ein eigenes System für die Benutzer- und API-Schlüsselverwaltung entwickelt werden muss.
Im Allgemeinen wird die Benutzerverwaltung dezentralisiert, was es schwierig macht, den Überblick über die aktuellen Benutzer, die derzeit aktiven API-Schlüssel und die verschiedenen Berechtigungen der API-Schlüssel zu behalten, sofern diese überhaupt verwaltet werden können.
Schwierige Kostenverfolgung
Die Dezentralisierung ist auch eine Herausforderung, wenn es um die Kostenverfolgung über verschiedene Anbieter hinweg geht. Oft ist es nur möglich, die Kosten pro Anbieter und pro API-Schlüssel zu verfolgen. Dies führt zu einem Mangel an Transparenz bei der Messung der Kosten der verschiedenen Anwendung oder der agentenbasierten Workflows. Außerdem ist es nicht möglich, in einer Multi-Provider-Architektur angemessene Budgets festzulegen. Zwar unterstützen die meisten Anbieter die Festlegung von Budgets pro API-Schlüssel und pro Konto, doch ist es schwierig, die Budgets über alle Anbieter hinweg zu kumulieren, was zu einer ineffizienten Kostenverwendung führt. Darüber hinaus ist es auch schwierig, die Nutzung jedes Modells zu verfolgen und zu überwachen und sich einen Überblick über die insgesamt verarbeiteten LLM-Tokens zu verschaffen. Dies wäre besonders nützlich, wenn Sie LLMs vor On-Premise ausführen, da die Token-Nutzung in direktem Zusammenhang mit der Ressourcennutzung und damit den Kosten steht. Dadurch ist es möglich, eine angemessene Preisschätzung für On-Premise LLMs vorzunehmen.
Wie LiteLLM diese Herausforderungen löst
Um die Herausforderung dezentraler LLM-Anbieter zu lösen, wird eine Art Gateway benötigt, um unseren Zugriff auf die verschiedenen Modelle der benutzten Anbieter zu zentralisieren. Aus diesem Grund wurde das Open-Source-Projekt LiteLLM ins Leben gerufen. Die Kernfunktion besteht darin, als zentrales Gateway zu dienen, in dem alle APIs der benutzten LLM-Anbieter zusammenlaufen und zu einer einzigen OpenAI-kompatiblen API „zusammengeführt” werden.
LiteLLM unterstützt alle großen Anbieter wie OpenAI, Azure, Anthropic, Google Gemini, und viele mehr. Es unterstützt auch lokale LLMs, die von vLLM oder Ollama bereitgestellt werden. Die Konfiguration erfolgt über eine einzige Konfigurationsdatei, in der die verschiedenen Endpunkte, Einstellungen und verfügbaren Modelle der verwendeten LLM-Anbieter angegeben werden.
Neben dem einheitlichen Gateway bietet es auch Lösungen für die anderen Herausforderungen, die beschrieben wurden, wie z. B. die Verwaltung von Benutzern und API-Schlüsseln sowie einen zentralisierten, detaillierteren Ansatz zur Messung der Kosten. Diese beiden Funktionen werden in diesem Blog-Artikel ausführlicher behandelt. Die Open-Source-Version von LiteLLM bietet außerdem eine Vielzahl weiterer nützlicher Funktionen für einen LLM-TechStack, wie z. B. Lastenausgleich zwischen Modellen, Guardrails, Response-Caching mit Vektordatenbanken oder die Verwaltung von MCP-Servern. Außerdem integriert sie andere Software und Dienste wie Langfuse, DataDog, Weights & Biases oder OpenTelemetry.
Es gibt auch eine Version von LiteLLM, welche sich an Unternehmen richtet und weitere Funktionen wie SSO, die Gruppierung von Teams in Organisationen, Audit-Protokollierung und detailliertere Sicherheits- und Compliance-Kontrollen enthält.
Eine einheitliche API für alle Ihre LLM-Anbieter
Die Kernfunktionalität von LiteLLM besteht darin, einen OpenAI-kompatiblen API-Endpunkt für mehrere Modelle und LLM-Anbieter bereitzustellen. LiteLLM nutzt dazu die Anmeldedaten Ihrer Anbieter, um die verschiedenen Anbieter-APIs aufzurufen. Die Software verwendet eine Lookup-Tabelle, um die unterstützten API-Parameter und die Kosten der verschiedenen Modelle zu ermitteln. Auf grob sieht die Architektur für die einheitliche API wie folgt aus:
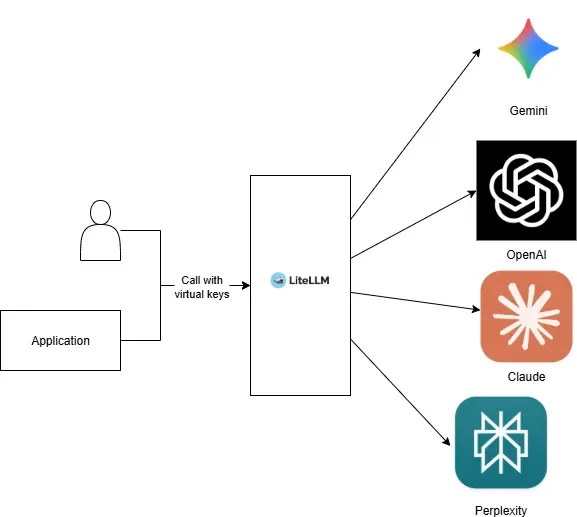
Da LiteLLM eine einzige OpenAI-kompatible API bereitstellt, sind nur sehr wenige Softwareänderungen erforderlich, da gängige SDKs und Bibliotheken bereits eine OpenAI-kompatible Schnittstelle erwarten. LiteLLM selbst bietet auch ein SDK, um Modell-APIs über das Gateway aufzurufen. Es ist auch einfacher, in Ihrer Anwendung zwischen verschiedenen Modellen verschiedener Anbieter zu wechseln, da in den meisten Fällen nur der Modellname im API-Aufruf geändert werden muss, wenn ein Modellwechsel gewünscht ist.
Benutzer-Self-Service und interne Benutzerverwaltung
Es ist möglich, die integrierte Benutzerverwaltung von LiteLLM zu nutzen, um verschiedene Benutzer mit unterschiedlichen Berechtigungen anzulegen und so den Zugriff auf bestimmte Modelle zu beschränken.
Sobald ein Benutzer angelegt ist, kann er mehrere „virtuelle” API-Schlüssel generieren, die dann zur Authentifizierung gegenüber dem LiteLLM-Gateway und für API-Aufrufe an die gewünschten Anbieter verwendet werden. So kann auch die API von LiteLLM benutzt werden, um virtuelle API-Schlüssel oder Benutzer programmgesteuert anzulegen. Dies ist besonders nützlich, wenn ein automatisiertes System für die Benutzeranlage erstellt wird. Für Unternehmen unterstützt LiteLLM auch die Benutzerverwaltung über SSO mit Microsoft Entra ID.
Es ist auch möglich, mehrere Benutzer in Teams und mehrere Teams in einer Organisation zu gruppieren. Dies bietet eine Möglichkeit, Ihre Unternehmensstruktur darzustellen, und erleichtert die Zugriffskontrolle, da Berechtigungen und zulässige Modelle auch auf Team- oder Organisationsbasis festgelegt werden können. Das Hierarchiesystem in LiteLLM sieht wie folgt aus:
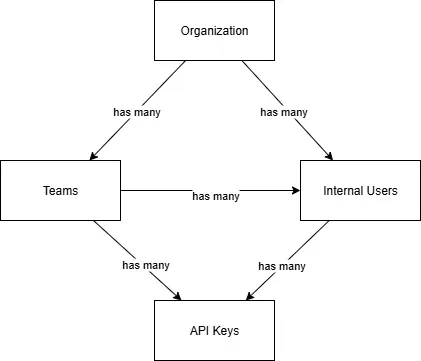
Das bedeutet, dass eine Organisation mehrere Teams oder Benutzer umfassen kann. Ein Team kann mehrere Benutzer umfassen, und ein Benutzer oder ein Team kann mehrere virtuelle API-Schlüssel haben. Insgesamt rationalisiert und vereinfacht dies die Benutzerverwaltung und die Benutzererstellung bei der Arbeit mit mehreren LLM-Anbietern.
LiteLLM-Budgets und Kostenverfolgung
Da jede Anfrage über Ihr Gateway läuft, ist es einfacher, die Kosten und die Nutzung Ihrer Modelle zu verfolgen. Es ist möglich, die Kosten pro Benutzer, virtuellem Schlüssel, Team oder Organisation zu verfolgen. Für jeden Teil der Hierarchie kann ebenfalls ein Budget festgelegt werden. LiteLLM unterstützt sogar ein „globales” Budget für alle bestehenden Teams oder Organisationen. Budgets können mit Rücksetzungszeiträumen versehen werden, sodass das Budget automatisch regelmäßig zurückgesetzt wird. Budgets können auch als Warnmetrik verwendet werden, was hilfreich ist, um Warnmeldungen einzurichten, wenn ein Budgetgrenzwert überschritten wird.
Die meisten Modellanbieter veröffentlichen die Nutzungskosten ihrer Modelle. In diesem Fall werden die Kosten berechnet, indem Input- und Outputtokens gezählt und mit dem Kostenfaktor des Modells multipliziert werden, die von LiteLLM in einer Lookup-Tabelle gespeichert werden. Es ist möglich, eigene Preise festzulegen, die dann für die Kostenberechnung verwendet werden. Dies ist besonders nützlich für on-premise LLMs, um deren Token-Nutzung mit einem Preis versehen möchten.
Zusammenfassung
Wir haben eine mögliche einfache agentenbasierte Architektur mit mehreren Modellen diskutiert und dabei die Bedeutung der Integration verschiedener LLM-Anbieter in die Architektur hervorgehoben. Die Verwendung mehrerer Modelle und Anbieter kann zwar die Ergebnisse und die Kosteneffizienz Ihres agentenbasierten Workflows verbessern, bringt aber auch neue Herausforderungen mit sich, darunter unterschiedliche API-Plattformen, dezentrale Benutzerverwaltung und schwierige Kostenverfolgung. Diese Herausforderungen werden besonders schwierig, wenn Sie zusätzlich zu den in der Cloud angebotenen LLMs auch on-premise Modelle verwenden.
Die Herausforderungen können durch die Rezentralisierung der API-Plattform über eine Open-Source-Software namens LiteLLM gelöst werden, die verschiedene nützliche Funktionen für einen LLM-Stack bietet. Zu diesen Funktionen gehören eine zentralisierte Benutzer- und API-Schlüsselverwaltung mit der Möglichkeit, eine IAM-Hierarchie zu erstellen, eine bessere Modellnutzung und Kostenverfolgung über alle Ihre Anbieter hinweg sowie die Möglichkeit, lokale Modelle mit benutzerdefinierten Preisen zu versehen. Außerdem bietet sie die Möglichkeit, eine OpenAI-kompatible API bereitzustellen, die alle von Ihnen verwendeten LLM-Anbieter in einer einzigen API zusammenfasst.